

Optical character recognition (OCR) is a tool built into many modern image and document scanners, including many of the photocopiers in the district. While some of the scanners may have this feature turned on by default, consult the settings on your school’s photocopier to see if PDFs that are scanned are being scanned with OCR.
What are the benefits of using OCR? Simply put, having OCR enabled will allow you to select specific text from the PDF document as though you were working with any other document file.
In some cases, opening a non-OCR with Google Docs after it has been uploaded to Google Drive will run Google’s OCR engine on the document before converting the PDF to a Google Doc file.
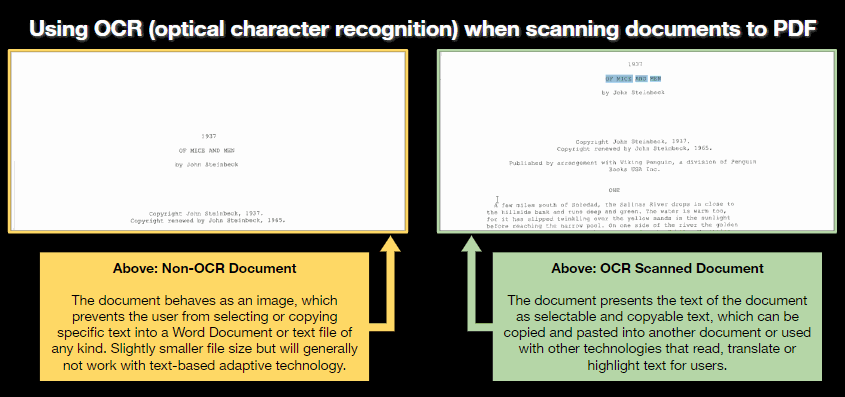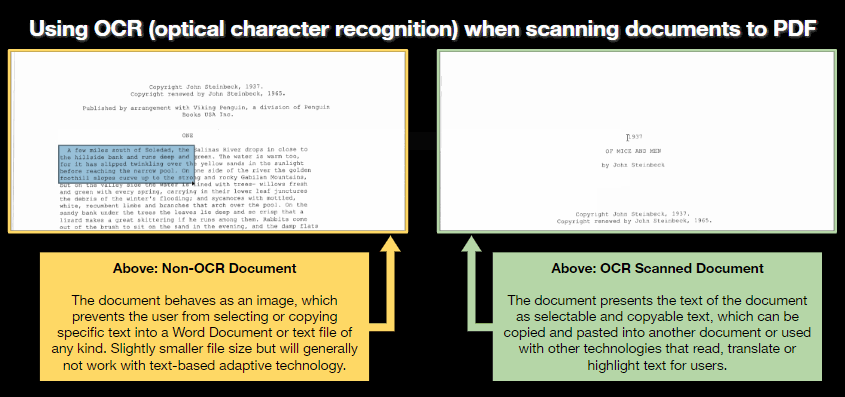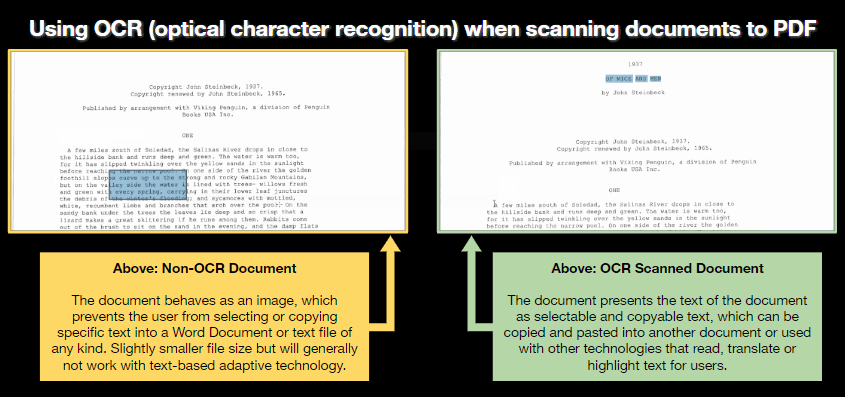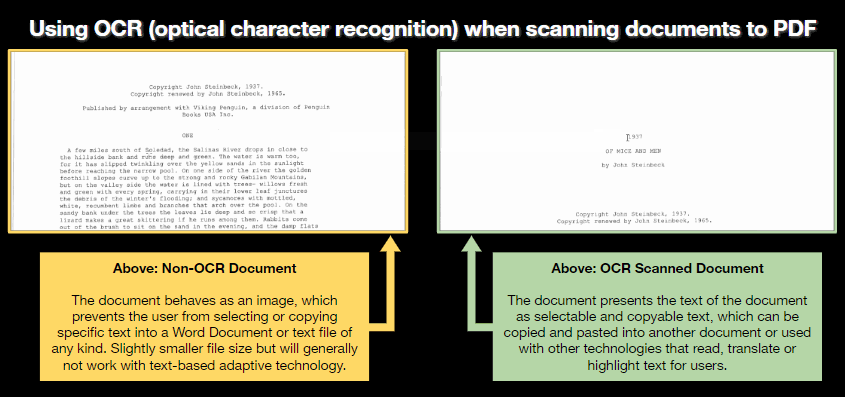
Comparing the difference between non-OCR and OCR-enabled PDF documents

In this image, a non-OCR scanned document behaves like a picture file, preventing the user from selecting text within the document. This may also prevent adaptive technologies from reading the PDF file aloud.

In this image, an OCR-enabled scan allows the user to select and copy text within the document. In some cases, other technology will be able to read this file aloud or convert the text into another language.